我全都要——2026年3月AI使用指南
ChatGPT、Claude、Gemini、Perplexity:四大AI平台的正确打开方式


最近 AI 圈最荒诞的一幕,大概就是"499 养龙虾,299 杀龙虾"。
OpenClaw 刷屏那阵子,前脚有人收 499 上门帮你装智能体,后脚就有人挂出 299 卸载服务。装一笔,杀一笔,热点还没退潮,产业链先闭环了。更讽刺的是,官方卸载命令就一行代码——299 块,买的是有人替你敲了一下回车。
好笑归好笑,但每轮 AI 热点都是这个剧本:一窝蜂冲进去,踩完坑一窝蜂退出来,花出去的钱和时间全成学费。真正成熟的不是产品,是围着风口转的收割方式。
热闹散了你会发现,能留下来的从来不是最炫的概念,而是足够稳定、足够省心、能真正嵌进日常工作的方案。这篇文章想聊的,正是热潮退去之后的问题:对不想过度折腾、但希望认真用好 AI 的普通用户来说,什么样的使用方案才是真正成熟的?

别再问"哪个AI最强"了,这个问题已经过时
ChatGPT 出到 GPT-5.4,Claude 推了 Opus 4.6,Google 把 Gemini 升到了 3.1 Pro,Perplexity 也早已不是当初那个套壳搜索引擎——四家的模型都够聪明了。聪明本身不再稀缺。
稀缺的是什么?是一套不用每两周推翻重来的使用方法。
你在社交媒体上看到的永远是噪音:今天有人吹 Claude 的文笔,明天有人捧 Gemini 的上下文长度,后天 Perplexity 又发了个新功能。如果你跟着这些信息走,每星期都在重新选平台、重新学功能、重新调整用法。真正的成本不是每月那几十块钱订阅费,而是你的时间和注意力被无休止的"AI 军备竞赛"消耗掉了——这和花 499 追着装 OpenClaw、再花 299 慌忙卸掉,本质上是同一种消耗。
这篇文章想做的事情很简单:给你一套可以至少稳定使用三到六个月的方案。
不是排行榜——那种东西下个月就过期。不是参数盘点——你不需要知道哪个模型在哪个 benchmark 上多了两个百分点。这是一份消费级使用方案,面向一种很具体的人:你愿意为 AI 付费,你想把它变成日常工具而不是隔三差五的新鲜玩具,但你也不想每个月都折腾一轮"到底该订哪个"。
先把结论亮出来:对大多数这样的用户,最合理的做法不是把预算砸在某一家的高阶计划上,而是用四个平台各自的初级付费计划,组成一个分工明确的系统。
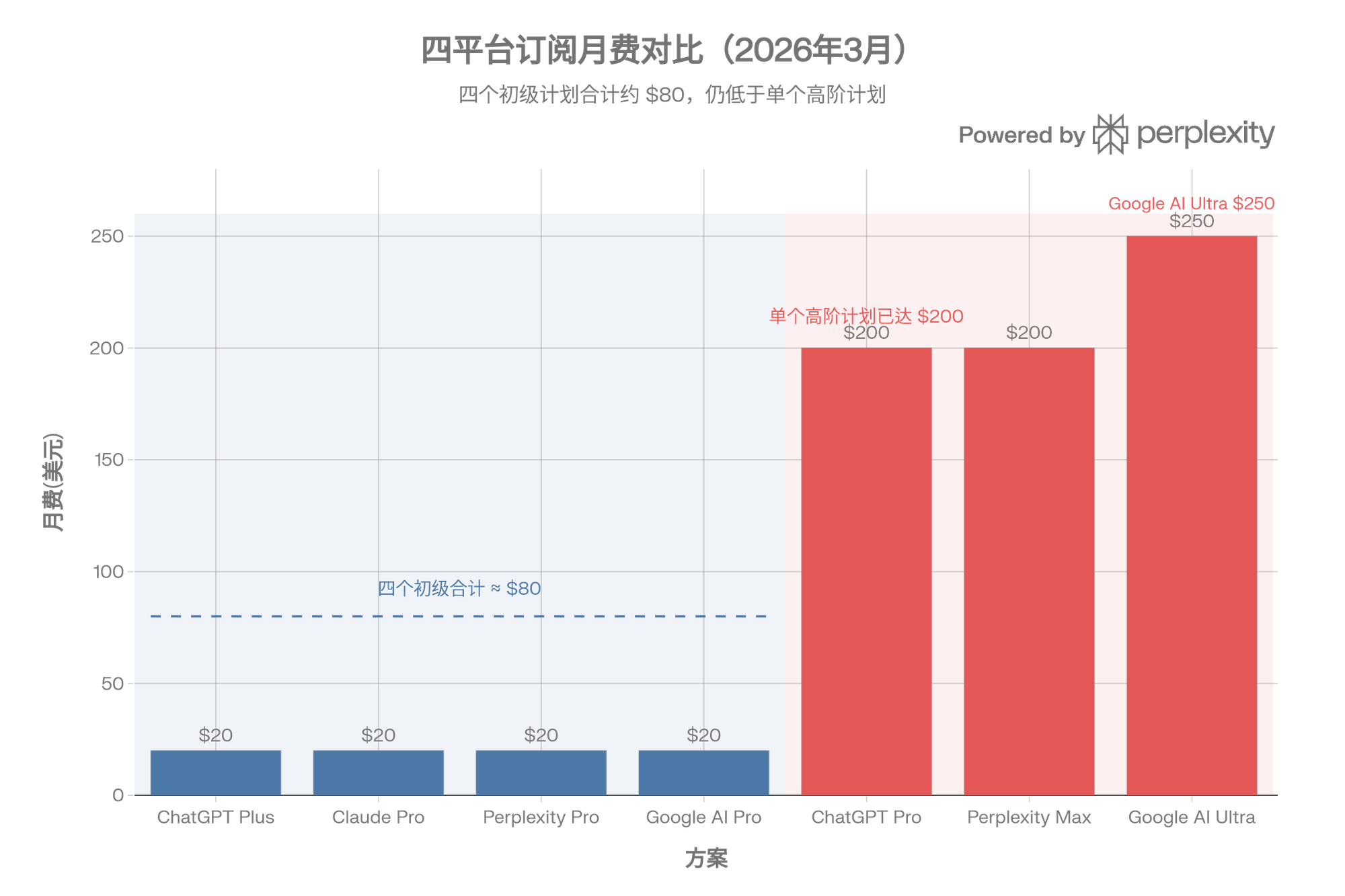
四个初级计划月费合计约 80 美元。而任何一家高阶计划——ChatGPT Pro 要 200、Google AI Ultra 要 250、Perplexity Max 也要 200——随便挑一个就超过四家初级加在一起的总和。
但这不是一道算术题。80 美元买到的不是"四倍的聪明",而是四个不同工种的人。你买的是一个搜索员、一个研究员、一个资料员、一个编辑——他们各管一摊,谁也替代不了谁。
下面我会把这个方案从底层逻辑讲到具体操作。你看完就能用起来——而且不用担心下个月又得花 299 把它卸了。
一、花80块还是花200块,先把这笔帐算明白
80 美元不算便宜,但比"花冤枉钱"便宜
每月 80 美元花在 AI 上,肯定不算省钱。但这个方案面向的不是想省钱的人,而是这样一类人:你已经决定认真用 AI 了,只是不想花了大价钱却发现大半功能用不上。
先看这张表,把帐算明白:
| 方案 | 月费 | 你实际得到什么 | 你实际用不上什么 |
|---|---|---|---|
| 四个初级计划组合 | ~$80/月 | 四种不同的工具形态:搜索、研究、资料库、深读深写 | 各家的最强模型档位和前沿实验功能 |
| ChatGPT Pro(单订) | $200/月 | GPT-5.4 Pro 模型、250 次 Deep Research/月 | GPT-5.4 Pro 下 Apps/Memory/Canvas/图像生成全部不可用;且没有其他三家的能力 |
| Google AI Ultra(单订) | $249.99/月 | Deep Think 推理、Gemini Agent、30TB 存储 | Deep Think 和 Agent 限美国+英语;30TB 存储和 YouTube Premium 不是 AI 核心能力 |
| Perplexity Max(单订) | $200/月 | 无限 Research/Labs、Computer 自动化 | Computer 仍在早期且仅桌面端;其余能力在 Pro $20 就有 |
| Claude Max(单订) | $100 或 $200/月 | 5 倍或 20 倍的消息用量 | 模型能力和 Pro 完全一样,只是量更大 |
高阶计划当然有它的道理。但你仔细看就会发现,它们卖的东西主要就三样:更多配额、更高档模型、更多实验性功能。而这三样恰恰是大多数人日常用不满的。 你不太会每个月做 30 次以上的深度研究,不太会每天稳定用超 Claude Pro 每 5 小时 45 条的消息上限,也大概不需要一个还在早期的浏览器机器人替你操作网页。
如果你选年付,Claude Pro 和 Perplexity Pro 还有折扣,分别折到大约每月 17 和 16.7 美元,四家合计月均能压到 74 美元左右。
所以这不是"最便宜的方案",但如果你把钱花在真正用得上的地方,它可能是最不浪费的方案。
它们不是竞争对手,是同事
2024 年选 AI,思路是"谁最聪明选谁"。2026 年不一样了——各家的差异越来越不在"脑子"上,而在"手艺"上。每家都在围绕自己的长处搭工具链,彼此之间与其说是竞争对手,不如说更像一个团队里的不同角色。
| 平台 | 一句话定位 | 最强环节 | 最弱环节 |
|---|---|---|---|
| ChatGPT | 综合总工位 | 全链路覆盖:研究、分析、项目、编码都有入口 | 文字质感不如 Claude,搜索速度不如 Perplexity |
| Claude | 深读员 + 高级编辑 | 长文本理解、高质量写作、代码审查 | 没有自动多来源研究工具,消息配额较紧 |
| Gemini | Google 生态资料工作台 | Gmail/Drive/Docs 联动、NotebookLM 资料库 | 中文写作纹理偏弱,超长上下文衰减严重 |
| Perplexity | 搜索前哨 + 资料压缩器 | 快速多来源搜索、带引用的结构化概览 | 不适合最终成稿,文件上限小,不能当项目中心 |
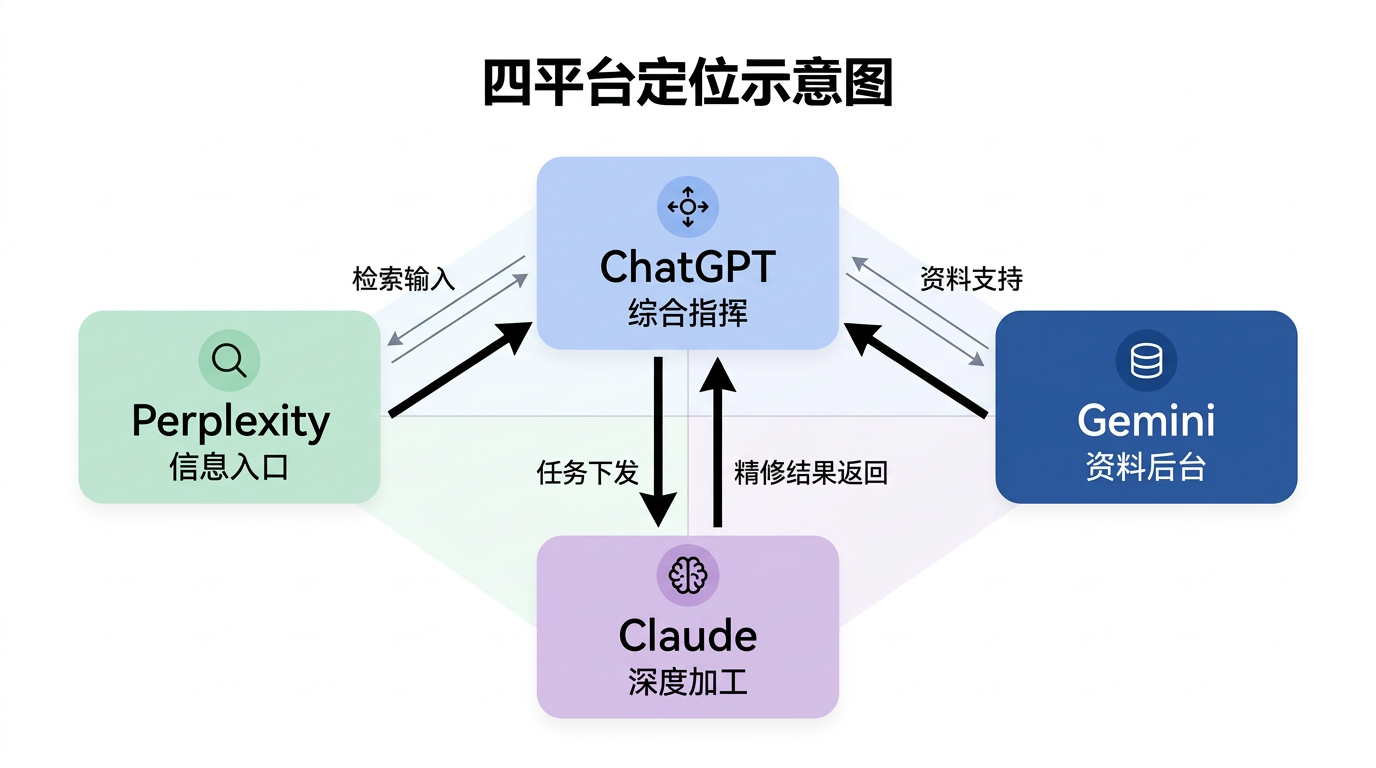
试图让一个平台从头包到尾,不是做不到,但你会花大量时间跟它的短板较劲。让搜索的人搜索,写字的人写字,整资料的人整资料——这才是"四个都订"的真正价值。
二、四个人,各是什么脾气
ChatGPT:什么都能干,但不是什么都干得最好
ChatGPT 是大多数人的 AI 起点,到了 2026 年 3 月它仍然是功能最全的那一个。但"最全面"和"每方面最强"是两回事,把这个区别搞清楚才能用好它。
它的主干模型现在是 GPT-5.3 Instant(快但轻)和 GPT-5.4 Thinking(慢但深),系统会自动切换。GPT-5.4 Thinking 不太"会写"——别指望它出来的文字有什么文采——但它特别能"讲清楚"。复杂问题到了它手里,会被拆成几层,压成一版结构完整、逻辑严密、差不多可以直接拿去用的回答。写政策解读、技术方案、课程讲解、把一堆乱笔记整理成文档——这些活它干得又快又稳。
说得直白一点:GPT-5.4 Thinking 像一个高级顾问,不像一个作家。 你能拿到很干净的结论,但文字本身不会让你觉得"这段写得真好"。
Deep Research 是 Plus 用户手里最值钱的功能。 你可以限定数据来源(指定网站、上传文件、已连接的第三方应用),研究开始前它先给你看计划、你改完再跑,过程中还能打断调整。最后出来的报告带引用,能导出 Markdown、Word、PDF。在四家平台的研究工具里,这套流程的可控性排第一。
但它不是没有天花板。Plus 计划下的关键限制:
| 限制项 | 具体数值 |
|---|---|
| GPT-5.3 Instant 消息上限 | 每 3 小时有限额,超了自动降级到 mini |
| GPT-5.4 Thinking 手动选择 | 每周有限额 |
| Deep Research 额度 | 每月 10 次全量 + 15 次轻量版 |
| Projects 文件数 | 每项目 20-25 个文件,一次最多传 10 个 |
| 单文件大小上限 | 512MB |
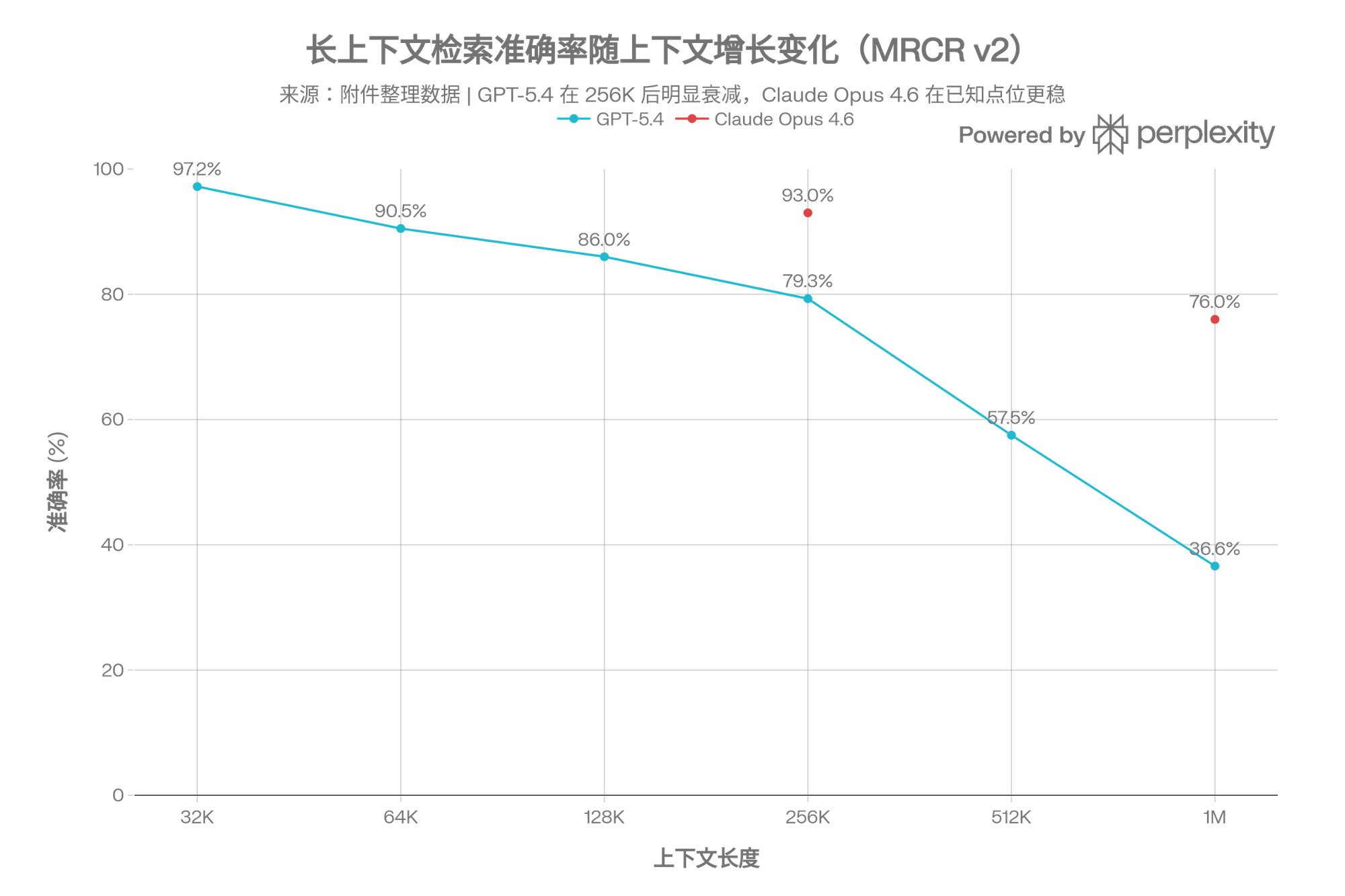
还有一个容易忽略的问题:GPT-5.4 处理长文本时,128K token 以内很可靠(检索准确率 86%+),但过了 256K 就开始明显掉链子,到 512K-1M 范围准确率只剩约 36%。所以别往里面一次塞太多东西指望它全消化——它更适合"中等长度资料的高质量分析",而不是"吞下一整本书"。
一句话:ChatGPT 是你的总控台。 接活、定义问题、做有控制的深度研究、管理多天的项目——这些事交给它最顺。但最好的文字质感和最强的超长文本深读,不在它这里。
Claude:安静,但交稿的时候让你眼前一亮
每个团队都有一种人——不爱抢话,给他一沓材料他能安安静静读完,回来给你一版让人眼前一亮的东西。Claude 就是这个角色。
它有两个模型:Opus 4.6 和 Sonnet 4.6。不是"好的和差的",是"慢工出细活"和"又快又稳"。
Opus 4.6 是当前所有主流 AI 模型里,写出来的文字最像人的。 这话我不是随便说的。你把同一段材料分别喂给 GPT-5.4 Thinking、Gemini 3.1 Pro 和 Claude Opus 4.6,让它们各写一版,区别是肉眼可见的。GPT 出来的像咨询报告,Gemini 出来的像高级课件,Opus 出来的——段落有推进、有停顿、有轻重起伏,语气层次和修辞节奏都比别家自然。要写评论、演讲稿、有说服力的长文、或者把一份枯燥报告改写成人愿意读的版本,首选它。
它的毛病也直说:有时候想太多,绕一圈才回到重点。你不给约束它就倾向于考虑得特别全,偶尔会显得不够利落。但如果你本来就要深思熟虑而不是快速出活,这反而是优点。
Sonnet 4.6 是日常干活最让人省心的默认选手之一。 它比 Opus 更干脆,比 Gemini 更自然,做代码解释、技术文档、工程邮件、项目说明这些活特别稳。文字谈不上多有光泽,但胜在可靠——你交给它的东西不会出什么幺蛾子。
| 模型 | 写作风格 | 像谁 | 最适合 | 主要短板 |
|---|---|---|---|---|
| GPT-5.4 Thinking | 克制、专业、任务导向 | 高级顾问 | 分析方案、政策解读、结构化文档 | 有时太像顾问稿,缺少温度 |
| GPT-5.4 Pro | 更稳更深,成稿完成度高 | 高级分析师 | 正式报告、一次性高质量交付 | 简单任务也容易"用力过猛" |
| Claude Opus 4.6 | 沉着、自然、有节奏 | 资深作者 | 评论、演讲稿、长文润色、叙事写作 | 偶尔绕弯子,不够利落 |
| Claude Sonnet 4.6 | 利落、稳定、偏工程 | 强工程师兼好编辑 | 技术文档、代码解释、README | 文字高级感不如 Opus |
| Gemini 3.1 Pro | 正确、整洁、概念型 | 高质量课件 | 概念说明、跨学科综合、原型描述 | 中文缺少纹理,读着像教材 |

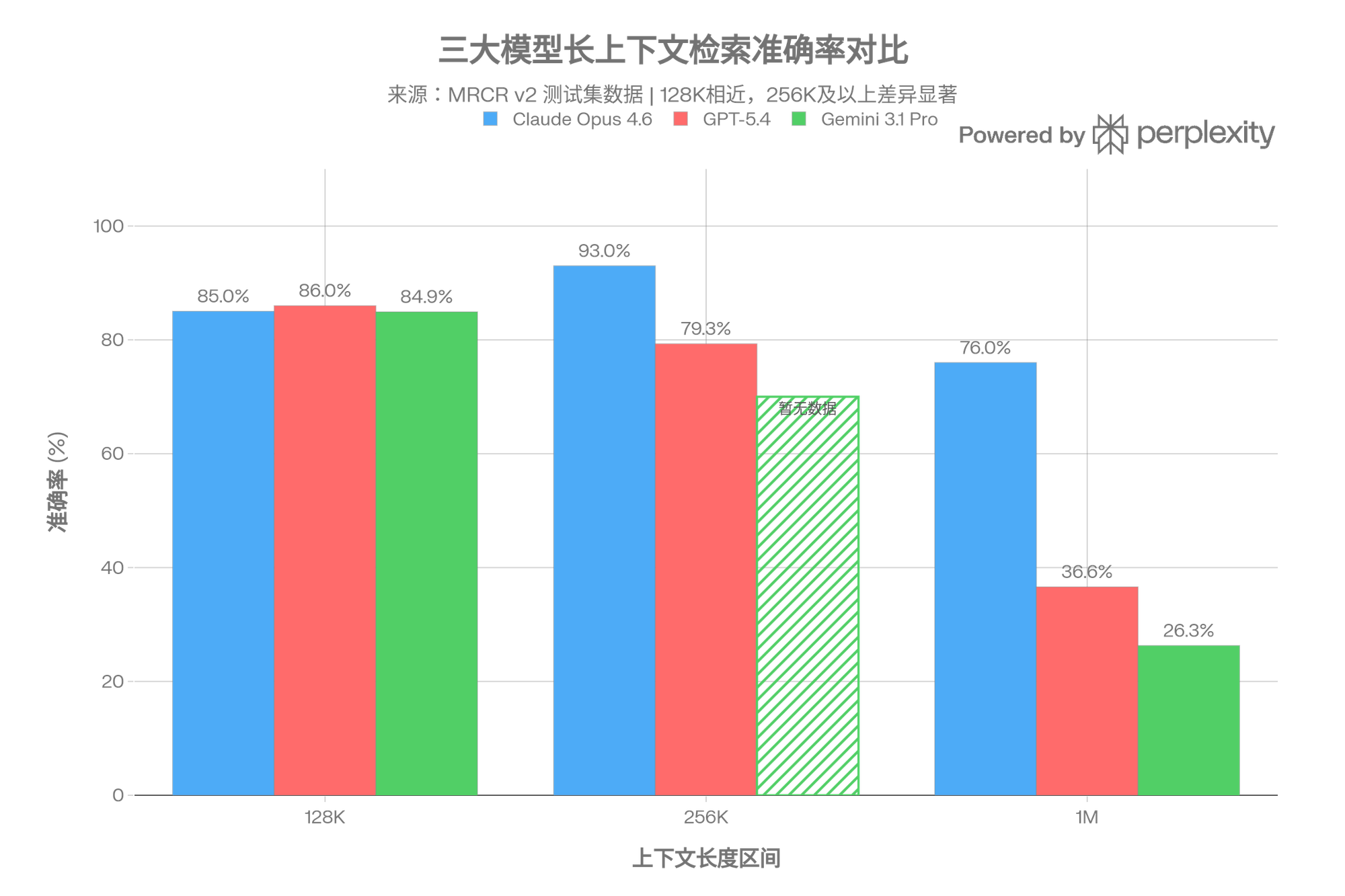
在读长文本这件事上,Claude 是目前消费者端最强的。 Opus 4.6 标准模式支持 200K token 上下文,这个范围内非常可靠。拿最吃性能的 MRCR v2 8-needle 测试来说——这个测试把 8 个关键信息藏进海量文本里看模型能不能全找回来——Opus 4.6 在 256K 范围拿到约 93% 的准确率,在 1M 范围拿到 76%,是唯一一个在超长上下文下还能保持高水平的模型。同范围里 GPT-5.4 大概 37%,Gemini 3.1 Pro 只有 26%。
不过 1M 上下文在消费者端还是 Beta,日常能稳定用的是 200K 以内。但 200K 已经够读一份几万字的长报告或者翻一遍一个中型代码库了。
Claude Code 是另一块值得单独提的能力。它不是聊天框里帮你写几行代码那种,而是一个坐在你终端里的工程助手——能读整个代码仓库、改文件、跑命令。对需要在仓库级别做修改的工程任务,它比在聊天里复制粘贴代码高效得多。
边界在哪里? Claude Pro 每 5 小时大约 45 条消息,消息越长、附件越大,实际条数越少。Claude 和 Claude Code 共享额度——两边不能同时猛用。另外,Claude 没有像 ChatGPT Deep Research 或 Perplexity Research 那样的"自动帮你搜几百个网页再出报告"的研究工具。它擅长的是你把材料喂给它之后的深度加工,不是自己出去找材料。
一句话:Claude 是你的深读员和高级编辑。 有长材料要认真消化、有文字要认真打磨、有代码仓库要深度改造——找它。但别指望它帮你搜索,也别把它当万能工位。
Gemini:写作一般,整资料一流
很多人对 Gemini 的印象还是"Google 做的另一个聊天机器人"。这个理解不能说错,但忽略了它真正的差异化:它是唯一能直接钻进你 Google 全家桶里帮你干活的 AI。
你平时用 Gmail 收邮件、Google Drive 存文件、Google Docs 写文档、Google Calendar 排日程的话——Gemini 有一个别家做不到的事:直接读取你这些地方的数据。
Gemini Deep Research 允许你在做研究的时候把 Gmail、Drive、上传文件和 NotebookLM 笔记本都纳入数据来源。研究做完,直接导出到 Google Docs。从搜集到整理到交付,整条链路不用搬运数据。对于深度依赖 Google 生态的人来说,这个体验别家给不了。
NotebookLM 值得多说几句。 它不是聊天机器人,是一个"以你的资料为圆心的问答库"。你把 Docs、PDF、网页、YouTube 视频、音频、图片导进去,然后就可以针对这些资料提问,它回答的时候会标注"这个信息来自你的哪个来源"。而且它支持选择输出语言——手头全是英文资料但要用中文写作?先在 NotebookLM 里把关键信息用中文问出来,效率比你自己一边读一边翻译快得多。
Gemini 3.1 Pro 在模型层面的强项是概念整合——遇到需要把好几个维度的信息拼在一起理解的问题,它通常能比较快地捋出结构。但如果你单看它写出来的中文,会觉得"都对,就是读着像教材"——整洁、正确,但缺少纹理感。英文好一些。
长上下文方面,它的表现很典型:中距离特别强,远距离断崖式下跌。 在 128K token 以内,检索准确率和 Claude 并列最高(约 85%)。但到了 1M token,骤降到约 26%——只能找回四分之一的目标信息。所以不要被"1M 上下文窗口"的标称数字唬住,真正好用的范围就在 128K 以内。
现实边界需要留意几个坑。 Google AI Pro 计划下,Gemini 3.1 Pro 每天 100 个 prompt,用完就得切到能力更弱的 Fast 模式。最吸引人的几个功能——Gemini Agent、Deep Think 推理模式——只给 Ultra 用户($249.99/月),而且限定美国地区、仅支持英语。NotebookLM 的 Cinematic Video Overviews 也一样。你在宣传页上看到的和你实际能用到的,中间隔着一道不小的门槛。
一句话:Gemini 是你的资料工作台。 资料散落在 Google 生态里需要整理、需要一个"可引用资料库"来支撑写作——找它。但别指望它帮你写好中文长文,也别被 1M 上下文的标称数字忽悠。
Perplexity:最快的开场,但不是终场
Perplexity 是四家里最容易被误解的。很多人把它当"另一个 ChatGPT"来用,然后觉得"也没什么嘛"。这就像拿锤子去拧螺丝,然后抱怨锤子不好使。
Perplexity 的真正身份不是聊天机器人,是搜索入口和资料压缩器。
它做得最好的事情是:你给它一个问题,它几秒钟之内从几十个来源里抓取信息、整合成一份带引用的概览。刚接触一个新话题、需要快速摸清"目前是什么状况、有哪些主要说法、关键来源在哪"——四家里面 Perplexity 最快,而且不是快一点点。
Research 模式更进一步:自动跑几十次搜索、读几百个来源,几分钟出一份综合报告。但这个模式你不能手动选底层模型,系统自动安排。Create Files and Apps(以前叫 Labs)在 Research 的基础上还能生成文件、表格甚至简单的互动网页。
有一件事必须讲清楚: 在 Perplexity 里用 GPT-5.4 或 Claude Sonnet 4.6 作为底层模型,你拿到的体验和在 ChatGPT 或 Claude 里直接用这些模型是不一样的。Perplexity 的搜索引擎、引用模板和模式路由会把不同模型之间的风格差异拉平。你得到的是"底模 × 搜索框架"的复合结果,不是模型原貌。
这不是缺点——Perplexity 的价值就在于搜索增益。它的工作不是自己写得好,而是先把外面的信息替你缩成一份更短、更干净、更可引用的材料。 然后你拿着这份材料去 ChatGPT 或 Claude 做深加工。
现实边界:
| 限制项 | 具体情况 |
|---|---|
| 文件上传 | 单文件 40-50MB(远小于 ChatGPT 的 512MB) |
| Research 额度 | 每月约 20 次,每天恢复 1 次 |
| 文件连接器 | Drive/Dropbox 可连但 Pro 不支持同步,文件更新要重新传 |
| Computer 代理 | 仅 Max 用户可用,Pro 不行 |
一句话:Perplexity 是你每个新任务的第一步。 搞清楚现状、搜集来源、拉出对比框架——从这里开始。但别在这里写最终稿,也别把它当项目管理中心。它是入口,不是归宿。
小孩子才做选择,成年人全都要
把四家的分工再过一遍——
| 你的需求 | 去找谁 | 一句话理由 |
|---|---|---|
| "这个话题现在是什么情况?" | Perplexity | 搜索最快,引用最全 |
| "这些资料说明了什么?帮我出份报告。" | ChatGPT | 研究可控,项目承载力最强 |
| "我 Gmail 和 Drive 里的东西太散了,帮我理理。" | Gemini / NotebookLM | 唯一能直接进 Google 生态的 |
| "这份材料帮我认真读一遍。这段文字帮我改好。" | Claude | 深读最强,文字质感最好 |
它们之间有重叠,但各自的"绝对优势区域"不冲突。理解了这一点就不用再纠结"到底选哪个"——因为答案是"全要,但各管各的"。
三、说完"是什么",说"怎么用"
为什么四个初级 > 一个高阶
在讲怎么用之前,再把订阅逻辑说透。这个选择会影响你后面所有的用法。
高阶计划卖的东西归纳起来就三样:更多配额、更强模型、更多实验功能。但你掰开看每一样:
配额: ChatGPT Pro 把 Deep Research 从每月 25 次加到 250 次——但你真做得完每月 250 次深度研究吗?Claude Max 把消息量放大 5-20 倍——但 Pro 每 5 小时 45 条消息,对不是全天候对话的人来说其实够用了。
模型: ChatGPT Pro 独占 GPT-5.4 Pro 模型——但这个模型不能用 Apps、Memory、Canvas 和图像生成,只是一个纯粹的思考引擎。对日常任务来说,GPT-5.4 Thinking 完全够胜任。
实验功能: Google AI Ultra 的 Gemini Agent 和 Deep Think 限美国+英语。Perplexity Max 的 Computer 还在早期。Claude Max 的 Claude in PowerPoint 还是 research preview。这些东西更像"下一代能力的预告片",不是今天能稳定依赖的生产力。
四个初级计划的价值不在于"便宜",而在于横向覆盖远大于纵向堆叠。你买的是四种不同形态的能力,不是同一种能力的 4 倍。
如果只记一张表,记这张
| 任务类型 | 交给谁 | 为什么 |
|---|---|---|
| 搜资料、找引用、搭对比表 | Perplexity | Pro Search 几秒出带引用概览,四家里速度最快 |
| 限定来源的深度研究 | ChatGPT | Deep Research 支持指定网站、控制来源、中途纠偏 |
| Google 生态资料联动 | Gemini / NotebookLM | 唯一能直接读取 Gmail/Drive/Docs 的平台 |
| 长材料深读、长文润色、表达精修 | Claude | Opus 4.6 的文字质感和长文本理解力当前无人能复制 |
| 最终统稿和输出交付 | ChatGPT | Projects + 导出功能让汇总和交付最顺畅 |
| 仓库级编码 | Codex / Claude Code | Codex 适合云端并行和 PR;Claude Code 适合终端深度工程 |
长资料任务还有一层隐性分流:
| 资料特征 | 首选平台 | 理由 |
|---|---|---|
| 中长材料高可靠分析(几万字以内) | ChatGPT 或 Claude | ChatGPT 更稳,Claude 更细 |
| 超长文本深读(十几万字级别) | Claude | 在超长范围的准确率远超其他 |
| 混合资料库问答(文档+网页+视频+音频) | Gemini / NotebookLM | 多模态来源整合最完善 |
| 外部信息压缩和快速检索 | Perplexity | 永远是最快的入口 |
四个平台各自的正确姿势和常见踩坑
知道"交给谁"还不够,还得知道"怎么交"。
ChatGPT:当任务指挥中心用,别当记事本用
开始一个新任务,先在普通聊天里把问题定义清楚——你要交什么、标准是什么、最终产出长什么样。然后根据任务切工具:要多来源阅读开 Deep Research,要跨天持续推进建 Projects,要改代码进 Codex。
Projects 被很多人低估了。你可以把项目指令写成长期偏好(格式、语气、引用方式),阶段性成果保存到 project sources,下次接着做时不用重新交代背景。
踩坑: 最常见的浪费是——所有事都在一个普通聊天窗口里干,不用 Deep Research 也不用 Projects,每次都从头解释一遍背景。这样做消息配额和上下文窗口全在重复消耗。
Claude:当编辑和审稿人用,别当搜索引擎用
你已经有具体材料了——长文档、需要改写的文字、需要审查的代码库——交给 Claude。Opus 做需要文采的活,Sonnet 做需要稳定执行力的活。
Claude Code 的正确姿势:先花几分钟把 spec 和验收标准写清楚,然后让它在仓库里执行。一边想一边改需求等于反复推倒重来,额度烧得飞快。
踩坑: 拿 Claude 做搜索。它现在所有计划都有 Web Search,但搜索不是它的强项,更没有像 Perplexity 那样的"自动读几百个来源出报告"的工具。用它搜索,你在用它的短板。
Gemini:当 Google 资料管家用,别当中文写手用
需要从 Gmail、Drive、Docs 里提取整合信息→ Gemini Deep Research。需要把多种来源做成可查询知识库→ NotebookLM。经常重复的轻任务(固定格式会议纪要、特定风格改写)→ 封装成 Gems。
NotebookLM 有一个关键技巧:选择 sources 子集。别每次问话都让它在全部来源里搜,选几个最相关的来源聚焦——回答更准,配额更省。
踩坑: 让 Gemini 做中文长文的最终润色。它概念整合能力确实强,但中文写出来读着就是像教材。这一步交给 Claude 或 ChatGPT。
Perplexity:当第一步用,别当最后一步用
不管后面要做什么——写文章、做研究、搭项目——先在 Perplexity 花几分钟搜一搜。Pro Search 建资料框架,Research 拿初版报告,然后带着这些成果去 ChatGPT 或 Claude 做深加工。
踩坑: 在 Perplexity 里从头到尾写完一篇文章。它的输出是"带引用的答案",不是"经过打磨的文章"。搜索和压缩是它的主场,成稿不是。
三条流水线,直接照着走
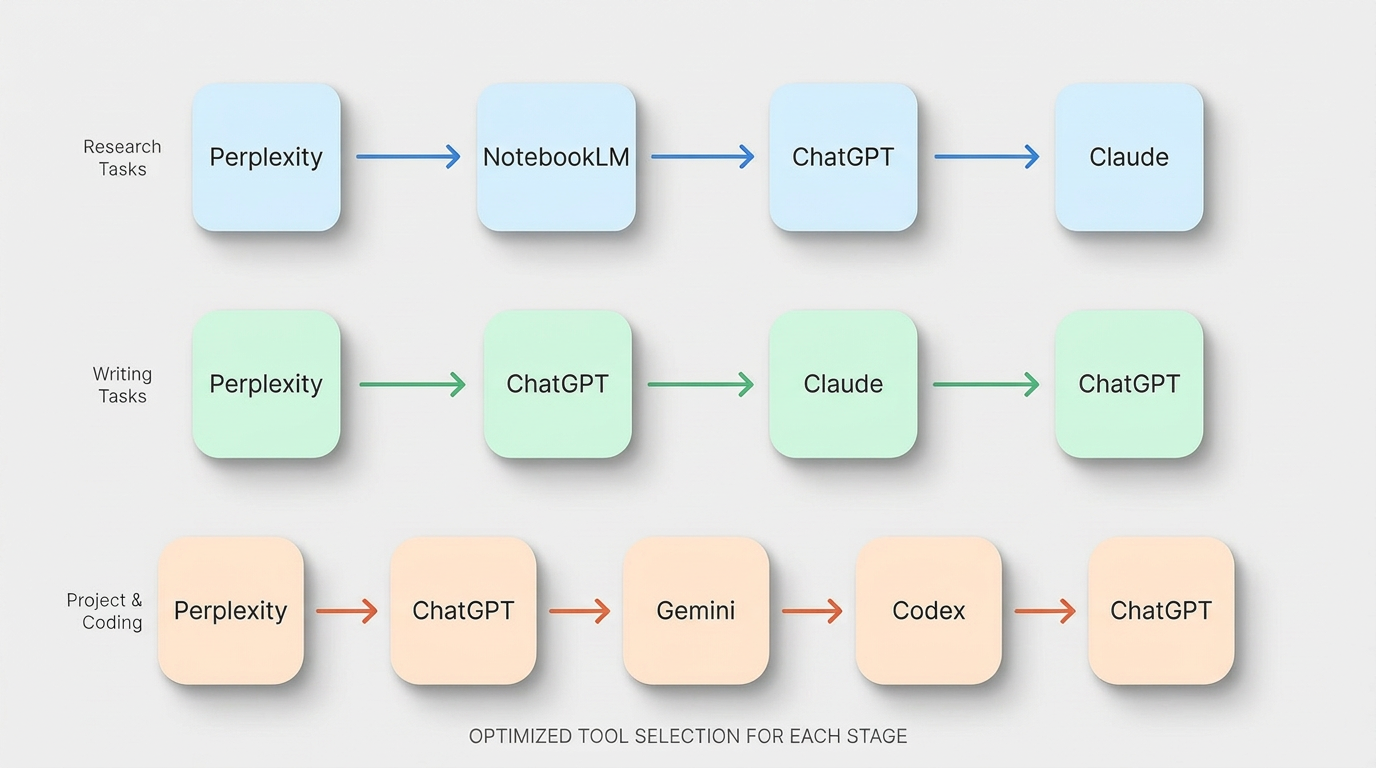
工作流一:研究型任务(调研一个话题、写研究笔记或报告)
① Perplexity Pro Search → 快速搜集,建资料框架
② NotebookLM → 导入核心资料,设输出语言为中文,形成可引用资料底座
③ ChatGPT Deep Research 或 Gemini Deep Research → 限定来源深入研究(Google 生态数据选 Gemini,其他选 ChatGPT)
④ ChatGPT Projects 或 Claude → 统稿(要结构清晰选 ChatGPT,要文字质感选 Claude)
工作流二:写作型任务(写文章、报告、项目说明)
① Perplexity → 补背景,确认事实和术语
② ChatGPT → 搭结构,定大纲,初步内容生成
③ Claude → 深化和润色(Opus 做文采部分,Sonnet 做技术部分)
④ ChatGPT → 最终统稿和格式化输出
工作流三:项目/编码型任务(把想法变成可运行的代码或工具)
① Perplexity → 查现状,有没有现成方案,常见的坑在哪
② ChatGPT → 定义需求和验收标准
③ Gemini / NotebookLM → 把技术文档、API 说明整理成可查询的资料库
④ Codex 或 Claude Code → 编码执行
⑤ ChatGPT → 输出说明文档和交付物
三条流里有一个一以贯之的原则:每一步找最合适的工具形态,不是找"最强模型"。 搜索的事别硬塞给 Claude,写作的事别让 Perplexity 收尾,资料整合别逼 ChatGPT 从零搜起。各人守好各人的位,整个流程就是顺的。
用三个月不崩溃的秘诀:节流、缓存、降级
工作流只是"怎么干"。要让这套系统跑三个月而不是三天,你还需要"怎么养"。
节流——贵的东西省着用
Deep Research、Research、Create、手动选 Thinking——这些都是高价值但高消耗的操作。日常的快问快答、框架搭建、小步迭代,交给快速模式(ChatGPT Auto/Instant、Gemini Fast、Perplexity Best)。只在"需要大量阅读、深度推理、正式交付"的关键节点才切到高成本模式。
| 平台 | 高成本模式 | 关键额度 | 日常替代 |
|---|---|---|---|
| ChatGPT | GPT-5.4 Thinking / Deep Research | Thinking 周限额;DR 每月 25 次 | Auto / Instant |
| Claude | Opus 4.6 长对话 | ~45 条/5h | Sonnet 4.6 轻任务 |
| Gemini | Pro 3.1 模型 | 100 prompts/天 | Fast 模式 |
| Perplexity | Research / Create | Research ~20 次/月 | Best / Pro Search |
缓存——做完的东西一定要存
这条可能是最多人忽略的。你花一次 Deep Research 额度拿到的报告、在 NotebookLM 整理好的资料结构、在 Claude 里润色完成的段落——这些东西做完就该存起来,而不是用完就关窗口。
ChatGPT 可以导出 Markdown/Word/PDF,也能保存到 Projects sources。Gemini Deep Research 导出到 Google Docs。Perplexity Research 和 Create 都支持导出。NotebookLM 的资料导入后可以反复查。
额度不够用,十次里有八次不是因为"额度太少",而是因为"上次的结果没存好",下一步不得不重新跑一遍。
降级——知道什么时候该换人
没有哪个平台的配额是无限的。碰到限制,别干等,切替代方案:
| 碰到什么情况 | 切到哪里 |
|---|---|
| ChatGPT 消息到上限 | 深度研究转 Perplexity Research 或 Gemini Deep Research |
| 文件太大 Perplexity 传不上去 | ChatGPT(512MB)或 NotebookLM(200MB/source) |
| Gemini 模型容量限制 | 同对话内切 Fast 模式继续 |
| Claude 消息用完 | 不需要深读深写的任务暂时转 ChatGPT |
| Perplexity Research 额度耗尽 | 用 Best 模式或 ChatGPT 普通搜索补上 |
把"限制"当成工作流设计的一部分来处理。四个平台加在一起的总容量,远远超过任何单一平台——这本身就是"四订方案"的又一层保障。
谁该用,谁别用
适合你的情况:
你愿意付费、认真使用 AI、需要研究+写作+整理+轻执行的综合能力、不想反复折腾。
不适合你的情况:
只想花最少的钱(那就只订一个 ChatGPT Plus)。只想用一个平台解决所有问题(那就选 ChatGPT,综合性最强)。追最前沿实验功能(那你需要某家高阶计划)。重度开发者需要 API 和自动化(本文只讨论消费者产品)。
方案本身的局限性:
每月 80 美元不是小钱。如果你某一项需求特别重(比如每天几十次深度研究),单一高阶计划可能更划算。很多让人兴奋的前沿功能都在高阶或 beta 里。API、本地模型和自建工具链不在讨论范围内。
知道方案的边界,才能在边界内把它用到最好。
结语:别追"最强AI"了,搭一套能长期干活的组合
写到最后,我想说一个可能让很多人不太舒服的判断:如果你到今天还在追问"哪个 AI 最强",你问错了问题。
不是这个问题不重要——两年前它确实是最重要的问题。但到了 2026 年,四家主流平台的模型都已经足够聪明了,聪明到了"谁比谁多几个百分点的跑分"对普通用户的日常使用几乎没有体感差异的程度。
真正造成巨大体感差异的,是你有没有一套稳定的使用方法。
同样是两个都订了 AI 的人,一个每隔两周换一次"主力平台"、每次看到新功能发布就焦虑自己是不是选错了、经常把同一份材料在不同平台之间反复搬运;另一个知道搜索去 Perplexity、研究去 ChatGPT、资料去 Gemini、深读深写去 Claude——后者花的钱可能更少,但产出稳定得多。差别不在工具,在方法。
这篇文章给出的"四个初级计划"方案,说到底就是这样一套方法。不是最便宜的方案,不是最极客的方案,不是最先锋的方案。但它稳定、统一、分工明确、决策成本低。你不用每天早上先花十分钟想"今天该用哪个 AI"——因为答案已经嵌在工作流里了。
AI 正在从"新鲜玩具"变成"水电煤"。你家里接水接电的时候,不会纠结"哪家自来水公司的水最好喝"——你只是确保水管通了、电闸没跳、燃气够用就行。AI 走向日常化的过程也是一样的:当它变成基础设施,你需要的就不再是"最新最酷的单品",而是一套接好管、不漏水、能长期用的系统。
这篇文章给的就是这套系统。
拿去用。不好用的地方,你自己调。过三个月再回来看看,大概率你已经跑出了自己的版本。

本文分析基于截至 2026 年 3 月的官方产品信息与实际使用经验。AI 平台更新频繁,建议做订阅决策前去各平台官网确认最新情况。

